#step1) 자릿수를 따로 분리하여 리스트화
def solution(x):
return[int(i) for i in str(x)]) #i가 문자열(x)일 동안 정수형 i를 리스트로 반환
solution(13)
#출력: [1,3]* len을 사용하지 않아도 str(x)만으로 1,3 순서로 감
#step2)합을 계산
def solution(x):
return sum([int(i) for i in str(x)])
solution(13)
#출력 : 4#step3) 조건지정 => 정답
def solution(x):
sum_x = sum([int(i) for i in str(x)])
if x % sum_x == 0:
return True
else:
return False* return 'true'로 했더니 따옴표가 같이 출력되어서 오답처리 됨. -> True, False로만 쓰니까 해결
# 다른 풀이
def solution(x):
return x%(sum(int(i) for i in str(x)))==0
def solution(a, b):
answer = 0
max_s = max(a,b)
min_s = min(a,b)
for i in range(min_s,max_s+1):
answer = answer + i
return answer
##### 다른 풀이 #####
def solution(a, b):
# a와 b 중 작은 수를 start로, 큰 수를 end로 설정합니다.
start = min(a, b)
end = max(a, b)
# start부터 end까지의 모든 정수의 합을 구합니다.
total_sum = sum(range(start, end + 1))
return total_sum
#step1)입력된 수가 짝수라면 2로 나누고, 홀수라면 3을 곱하고 1을 더하는 조건 작성
if num % 2 == 0:
num = num / 2
else :
num = (num * 3)+1#step2) 결과로 나온 수에 같은 작업을 500번 반복(이후에는 -1반환)
for i in range(500):
if num % 2 == 0:
num = num / 2
else :
num = (num * 3)+1
return -1#step3)1번에서 정리한 조건을 반복 적용했을 때 num이 1이 되면 돌아가던 횟수(i)를 출력
def solution(num):
for i in range(500):
if num % 2 == 0:
num = num / 2
else :
num = (num * 3)+1
if num == 1:
return i + 1
return -1#step4) num이 1일 때, 0을 반환 => 정답
def solution(num):
if num == 1:
return 0
for i in range(500):
if num % 2 == 0:
num = num / 2
else :
num = (num * 3)+1
if num == 1:
return i + 1
return -1
def solution(seoul):
answer = ''
for i in range(len(seoul)):
if seoul[i] == "Kim":
answer = f'김서방은 {i}에 있다'
return answer# 다른 풀이
def findKim(seoul):
return "김서방은 {}에 있다".format(seoul.index('Kim'))
# 실행을 위한 테스트코드입니다.
print(findKim(["Queen", "Tod", "Kim"]))
#나의 풀이
def solution(arr, divisor):
answer = []
for i in range(len(arr)):
if arr[i] % divisor == 0:
answer.append(arr[i])
answer.sort()
else:
continue
if answer == []:
answer.append(-1)
return answer#다른 풀이
def solution(arr, divisor): return sorted([n for n in arr if n%divisor == 0]) or [-1]
한 줄로 풀 수 있는 능력.. 부럽다.. 그거 어케하는건데....
Pandas 개인과제
문제1. 데이터 조회, 정렬, 조건 필터
- 출제의도
- 데이터를 조회, 정렬, 조건에 따른 필터링을 할 수 있다.
- 배경
- 타이타닉 데이터는 타이타닉호 생존자, 사망자에 관한 데이터입니다. 다음 컬럼 설명을 참고하여, 요구사항에서 요구하는 데이터를 조회하세요.
- 컬럼 (column) 설명
- survivied: 생존여부 (1: 생존, 0: 사망)
- pclass: 좌석 등급 (1등급, 2등급, 3등급)
- sex: 성별
- age: 나이
- sibsp: 형제 + 배우자 수
- parch: 부모 + 자녀 수
- fare: 좌석 요금
- embarked: 탑승 항구 (S, C, Q)
- class: pclass와 동일
- who: 남자(man), 여자(woman), 아이(child)
- adult_male: 성인 남자 여부
- deck: 데크 번호 (알파벳 + 숫자 혼용)
- embark_town: 탑승 항구 이름
- alive: 생존여부 (yes, no)
- alone: 혼자 탑승 여부
- 요구사항
- 나이가 20살 이상 40살 미만인 승객
- pclass가 1등급 혹은 2등급인 승객
- 열(column)은 survived, pclass, age, fare 만 나오게 출력
- 10개만 출력
- 다음 조건을 만족하는 코드를 입력하세요.
- Skeleton code
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')#내가 작성한 코드
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')
cond1 = (df[age]>= 20 & df[age]< 40)
cond2 = (df[pclass].isin([1,2]))
df.loc[:9, cond1 & cond2]
# NameError: name 'age' is not defined***수정 내용***
- age와 pclass는 데이터프레임의 컬럼이므로, df['age']와 df['pclass']로 접근
- 비트 연산자인 &를 사용할 때는 각 조건을 괄호로 묶어주기
- 위에서 10번째까지만 출력
# 중간 과정
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')
cond1 = (df['age']>= 20) & (df['age']< 40)
cond2 = (df['pclass'].isin([1,2]))
df.loc[cond1 & cond2].head(10)***수정 내용***
- 열(column)은 survived, pclass, age, fare 만 나오게 출력
# 제출 코드
import pandas as pd
import seaborn as sns
df = sns.load_dataset('titanic')
df1 = df.loc[:, 'survived':'fare']
cond1 = (df1['age']>= 20) & (df1['age']< 40)
cond2 = (df1['pclass'].isin([1,2]))
df1.loc[cond1 & cond2].head(10)
문제2. 데이터 합치기 및 컬럼 생성
- 출제의도
- 데이터를 합치고 조건에 따른 컬럼을 생성할 수 있다.
- 배경
- 간단한 고객 데이터와 주문 데이터를 합치고, 주문여부에 따라 고객을 분류하고자 합니다.
- 요구사항
- 고객 테이블(customers)를 기준으로 주문 테이블(orders)를 합쳐주세요. 주문 금액이 없는 고객도 모두 포함되어야 합니다.
- 주문 금액이 없는 경우, 0으로 표현하세요.
- 주문금액이 있는 경우 "구매", 주문금액이 0인 경우 "미구매"로 분류하는 "구매여부" 칼럼을 생성하세요.
- df출력 (결과칼럼: 고객번호, 이름, 금액, 구매여부)
- Skeleton code
import pandas as pd
import numpy as np
#고객 테이블
customers = pd.DataFrame({
'고객번호': [1001, 1002, 1003, 1004, 1005, 1006, 1007],
'이름': ['승철', '동경', '예나', '혜연', '장훈', '채운', '다연']
})
#주문 테이블
orders = pd.DataFrame({
'cno': [1001, 1001, 1005, 1006, 1008, 1001],
'금액': [10000, 20000, 15000, 5000, 100000, 30000]
})
# 중간 과정
#고객 테이블(customers)를 기준으로 주문 테이블(orders)를 합쳐주세요. 주문 금액이 없는 고객도 모두 포함되어야 합니다.**
#주문 금액이 없는 경우, 0으로 표현하세요.
#df출력 (결과칼럼: 고객번호, 이름, 금액, 구매여부)
df = pd.merge(customers,orders,left_on='고객번호',right_on='cno', how='left')
df.fillna(value=0)
df.drop(columns='cno')
#중간 과정2
#주문금액이 있는 경우 "구매", 주문금액이 0인 경우 "미구매"로 분류하는 "구매여부" 칼럼을 생성하세요.
df = pd.merge(customers,orders,left_on='고객번호',right_on='cno', how='left')
def a(df):
if pd.isna(df['금액']) :
df.fillna(value=0)
return '미구매'
else:
return '구매'
df['구매여부'] = df.apply(a, axis=1)
df.drop(columns='cno')
df
*** 문제점 ***
1. null값이 0으로 나타나지 않음
2. cno 컬럼은 출력하지 않아야함
3. 소수점 없애기
*** 문제 이유 / 해결 방안 ***
apply는 행/열별로 값을 변경하는데, fillna는 데이터 프레임의 값을 직접 변경해서 같이 쓰면 작동이 안됨.
-> .loc를 이용하여 작성
# 제출 코드
df = pd.merge(customers,orders,left_on='고객번호',right_on='cno', how='left')
df.loc[df['금액'].isna(), "구매여부"] = '미구매'
df.loc[df['금액'].isna(), "금액"] = 0
df.loc[df['금액'].notna(), "구매여부"] = '구매'
df['금액'] = df['금액'].astype(int)
df.drop(columns='cno')
문제3. iris 데이터 활용
- 출제의도
- 집계용 함수를 이용할 수 있다.
- 기초 통계량을 구할 수 있다.
- 상관관계의 개념을 이해하고, 코드를 이용해 상관관계를 구할 수 있다.
- 간단한 시각화를 할 수 있다.
- 배경
- iris 데이터셋은 붓꽃(iris) 품종 중 Setosa, Versicolor, Virginica 분류에 대한 로널드 피셔의 1936년 논문에서 사용된 데이터 셋입니다.
- 꽃받침(Sepal)과 꽃잎(Petal)의 길이 너비로 세개 품종을 분류하고 있습니다. 분류에 앞서, 꽃받침 넓이와 길이, 꽃잎의 넓이와 길이에 대한 기초 통계량을 확인하고자 합니다.
- 가장 상관관계가 높은 변수가 무엇인지를 찾고, 이를 시각화하고자 합니다.
- 요구사항
- 3-1) species별 sepal length, sepal width, petal length, petal width의 평균과 표준편차를 구하세요.
- 3-2) sepal length, sepal_width, petal_length, petal_length 4가지 변수 중 가장 상관관계가 높은 두 변수를 찾으세요.
- 3-3) 위에서 구한 두 변수를 x,y축으로 두고 species에 따라 분류하는 산점도를 생성하세요.
- Skeleton 코드
import pandas as pd
import numpy as np
import seaborn as sns
iris= sns.load_dataset("iris")
#3-1) species별 sepal length, sepal width, petal length, petal width의 평균과 표준편차를 구하세요.
import pandas as pd
import numpy as np
import seaborn as sns
iris= sns.load_dataset("iris")
iris_groupby = iris.groupby('species').agg(["mean","std"])
iris_groupby
#3-2) sepal length, sepal_width, petal_length, petal_length 4가지 변수 중 가장 상관관계가 높은 두 변수를 찾으세요.
iris_corr = iris_groupby.corr(method = 'pearson')
iris_corr
가장 상관관계가 높은(1에 가까운) 변수는 sepal_length와 petal_width
따라서 이 값을 x,y축으로 산점도를 그리면
plt.scatter(iris['sepal_length'], iris['petal_width'])
plt.show()
*** 수정 ***
species에 따라 분류해야하므로plt.scatter이 아닌 sns.scatterplot를 사용
sns.scatterplot(data=iris, x = 'sepal_length' , y= 'petal_width', hue='species', style='species')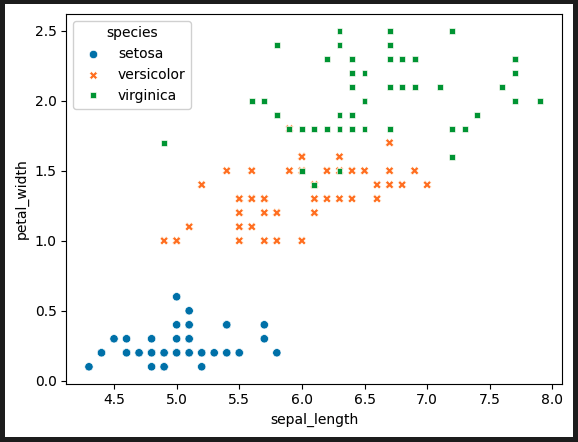
#제출쿼리
import pandas as pd
import numpy as np
import seaborn as sns
iris= sns.load_dataset("iris")
iris_groupby = iris.groupby('species').agg(["mean","std"])
iris_corr = iris_groupby.corr(method = 'pearson')
sns.scatterplot(data=iris, x = 'sepal_length' , y= 'petal_width', hue='species', style='species')https://dydatablog.tistory.com/76
[Python]산점도 plt.scatter과 sns.scatterplot의 차이
*plt.scatter과 sns.scatterplot의 차이plt.scatter: Matplotlib의 pyplot 모듈에서 제공하는 함수로, 기본적으로 단순하고 기본적인 스타일로 산점도를 그린다. 색상이나 스타일을 사용자 지정하려면 추가적인
dydatablog.tistory.com
'내일배움캠프 > TIL' 카테고리의 다른 글
| [TIL]기초 프로젝트_1주제선정, 알고리즘 코드카타 (0) | 2024.12.26 |
|---|---|
| [TIL]241224_코드카타, 개인과제4 (2) | 2024.12.24 |
| [TIL]241219_매개변수와 인자, 파이썬 제곱근 하는 법, 정렬 (1) | 2024.12.19 |
| [TIL]241217_알고리즘 코드카타 / Pandas 시작! (0) | 2024.12.19 |
| [TIL]241217_SQL, Python, Pandas의 역할 / SQL코드카타 / SQL퀴즈 오답노트 (2) | 2024.12.17 |