728x90
문제 상황 : product_type 컬럼 항목 중에 제대로 분류되지 않은 컬럼들이 있음

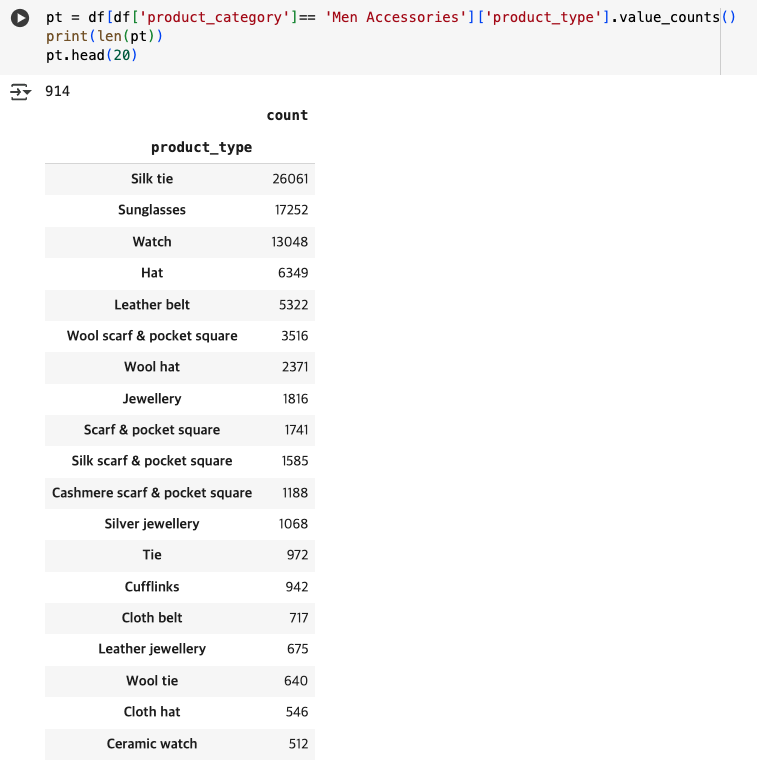
914개의 product_type을 공식 홈페이지에 나와있는 12가지의 카테고리로 분류

- ✅ Bags → 0개
- ✅ Small bags, wallets & cases → 0개
- ✅ Belt bags → 0개
- ✅ Belts → 7947개
- ✅ Sunglasses → 18477개
- ✅ Scarves & pocket squares → 8203개
- ✅ Ties → 27948
- ✅ Hats & pull on hats → 10139
- ✅ Gloves → 880개
- ✅ Cufflinks → 1631개
- ✅ Watches → 18957개
- ✅ Jewellery → 4596개
합계 : 98778개
men_accesories 총 개수 : 98779
차 : 1개

구글에 검색해보니 파우치인것을 확인 → bags로 분류
# men_watch : 18,957개
# 남성용 시계 필터링
men_watch = df[(df['product_gender_target'] == 'Men') &
(df['product_type'].str.contains('watch', case=False))]
# men_jewllery : 4,596개
# 남성용 jewellery 필터링
men_jewellery = df[(df['product_gender_target'] == 'Men') & (df['product_type'].str.contains('jewellery', case=False))]
# men_belt : 7,947개
# 남성용 belt 필터링
men_belt = df[(df['product_gender_target'] == 'Men') & (df['product_type'].str.contains('belt', case=False))]
# men_sunglasses : 18,477개
# men_sunglasses 필터링
men_sunglasses = df[(df['product_gender_target'] == 'Men') & (df['product_type'].str.contains('sunglasses', case=False))]
# men_scarves & pocket squares : 8,203개
# men_pocket 필터링
men_pocket = df[(df['product_gender_target'] == 'Men') & (df['product_type'].str.contains('scarf|pocket', case=False))]
#men_ties : 27,948개
# men_ties 필터링
men_ties = df[(df['product_gender_target'] == 'Men') & (df['product_type'].str.contains(r'\btie\b', case=False)) & (~df['product_type'].str.contains('sunglass', case=False))]
# men_Hats & pull on hats : 10,139개
# men_hats 필터링
men_hats = df[(df['product_gender_target'] == 'Men') & (df['product_type'].str.contains('hat', case=False))]
# men_cufflinks : 1,631개
# men_cufflinks 필터링
men_cufflinks = df[(df['product_gender_target'] == 'Men') & (df['product_type'].str.contains('cufflink', case=False))]
# 중복체크 / 미분류 데이터 처리
# 원본은 그대로 두고 df1 생성
df1 = df.copy()
# product_sub_category 컬럼 생성 (product_category 컬럼 우측에)
# 컬럼이 생성되는 위치 설정 : df.insert(loc(0부터 시작), column, value, allow_duplicates=False)
# df.columns.get_loc('컬럼명')+1 을 써서 그 컬럼 오른쪽에 삽입
df1.insert(df1.columns.get_loc("product_category") + 1, "product_sub_category", "")
df1.loc[df['product_id'].isin(men_watch['product_id']), 'product_sub_category'] = 'Watches'
df1.loc[df['product_id'].isin(men_jewellery['product_id']), 'product_sub_category'] = 'Jewellery'
df1.loc[df['product_id'].isin(men_belt['product_id']), 'product_sub_category'] = 'Belts'
df1.loc[df['product_id'].isin(men_sunglasses['product_id']), 'product_sub_category'] = 'Sunglasses'
df1.loc[df['product_id'].isin(men_pocket['product_id']), 'product_sub_category'] = 'Scarves & pocket squares'
df1.loc[df['product_id'].isin(men_ties['product_id']), 'product_sub_category'] = 'Ties'
df1.loc[df['product_id'].isin(men_hats['product_id']), 'product_sub_category'] = 'Hats & pull on hats'
df1.loc[df['product_id'].isin(men_gloves['product_id']), 'product_sub_category'] = 'Gloves'
df1.loc[df['product_id'].isin(men_cufflinks['product_id']), 'product_sub_category'] = 'Cufflinks'
#미분류데이터
# 'product_sub_category'가 null인 행 필터링
null_category_check = df1[df1['product_sub_category']=='']
# 두 조건을 결합하여 최종 필터링
men_null = null_category_check[null_category_check['product_category'] == 'Men Accessories']
# 원하는 열 선택
result_null = men_null[['product_id','product_type', 'product_name', 'product_category']]
# 결과 출력
result_null
# 'product_id'가 41638058인 행의 'product_category'와 'product_sub_category' 값을 변경
df1.loc[df['product_id'] == 41638058, 'product_sub_category'] = 'Bags'
# 결과 확인
df1[df1['product_id'] == 41638058]
# 데이터 저장
men_acc = df1[df1['product_category'] == 'Men Accessories']
# 파일로 추출
men_acc.to_csv("men_accessories- product_sub_category 분류.csv", index=False)728x90
'내일배움캠프 > TIL' 카테고리의 다른 글
| [TIL]250319_최종 프로젝트_군집을 위한 파생변수, 튜터링 노트 요약 (0) | 2025.03.19 |
|---|---|
| [프로젝트 회고] 실전 프로젝트(Tableau)_게임 유저 및 이탈 요인 분석 대시보드 (0) | 2025.03.14 |
| [TIL]250310_최종프로젝트 기획서, 데이터 전처리 (0) | 2025.03.10 |
| [TIL]250307_간단EDA(2), 시장조사, KPI 지표 고민.. (0) | 2025.03.07 |
| [TIL]250306_최종 프로젝트 간단 EDA, 배경설정 (0) | 2025.03.06 |