최종프로젝트 기획서 제출
더보기
프로젝트 제목
- 럭셔리 중고 플랫폼 Vestiaire Collective의 시장 점유율 확대 방안 및 신뢰도 강화 전략
프로젝트 주제
[개요]
- 중고 명품 플랫폼 Vestiaire Collective는 2022년 7월 27일 한국 시장에 진출했으며, 현재 2025년 IPO(기업공개)를 목표로 시장 점유율 확장에 주력하는 중. 이를 위해 브랜드 인지도 강화와 더불어, 소비자 신뢰 확보를 위한 전략을 세우고자 함.
[배경]
- 최근 물가 인상의 영향으로 중고 시장이 활성화되면서, 플랫폼의 매출 성장과 시장 점유율 확대가 중요한 과제가 되고 있습니다. 이에 따라, 소비자들이 중고 거래에서 가장 중요하게 여기는 ‘신뢰도’와 ‘안정성’을 높일 수 있는 전략을 세우고자 함
[주제]
- 판매자들이 최적의 가격을 설정하고, 빠른 판매 전략을 세울 수 있으며, 신뢰도 향상을 통해 수익을 극대화할 수 있는 전략을 제안함
[설명]
- 방안: 우수 판매자의 비율을 높이기 위하여 판매자 군집을 통한 우수 판매자 혜택 및 기준 강화, 제품 트렌드 대시보드 제공, 판매자 등급별 수익모델(수수료) 개선, 기존 가격 추천 시스템 개선
- 기타 개선방안: 카테고리 필터링(UI) 개선으로 제품 찾기 편의성 제공, 상품설명 및 키워드 추천 서비스, 정품 인증 서비스 개선, 판매 과정 개선
[데이터]
-https://www.kaggle.com/datasets/justinpakzad/vestiaire-fashion-dataset/code
Vestiaire Collective Dataset
Second Hand Luxury Fashion Data
www.kaggle.com
프로젝트 목표
- 명품 중고 거래 시장의 글로벌 점유율 확대를 목표로 한다. 중고 플랫폼의 특성상 신뢰는 플랫폼 성공의 핵심 요소이며, 우리는 판매자를 위한 차별화된 서비스를 제공하여 신뢰할 수 있는 우수 판매자들을 확보하고, 구매자 유입 및 플랫폼의 지속적인 성장을 촉진하고자 한다.
문제 정의
- 분석 및 시각화의 중점
- 중고 명품 트렌드 분석 대시보드를 활용하여 트렌드를 반영한 제품 판매
- 기업 입장에서의 판매자 관리를 위한 대시보드
- 문제의 필요성 및 중요성
- 명품 중고시장에서는 정품 신뢰도가 높은 플랫폼일수록 많은 유저를 끌어들일 수 있음. 현재 Vestiaire Collective의 구매자 입장에서는 정품 신뢰도와 관련된 컴플레인이 많음.
- 판매자 입장에서는 상품 등록까지 24시간 이상 걸리고, 각종 수수료가 많아 불만 쇄도 중. 신뢰성 확보를 위한 과정을 생략할 수 없으므로, 우수 판매자들이 느낄 수 있는 다른 메리트가 필요함
- 트렌드 분석 대시보드, 추천 시스템을 활용하여 판매자들에게 편의성 제공 + 우수 판매자 혜택 및 기준 강화, 수수료 변경을 통한 수익 개선
데이터 활용 계획
- 데이터 출처
- 데이터 전처리 및 분석 계획
- 결측치, 이상치 처리 및 주요 지표 선정
- 범주형 데이터 인코딩, 판매자 군집
- 대시보드 구성 계획
- 판매자를 위한 트렌드 대시보드: ◦ 제품 카테고리별 좋아요 수 ◦ 제품 상태별 좋아요 수 ◦ 색상별 좋아요 수 ◦ 재질별 좋아요 수 등
- Vestiaire 직원용 대시보드: ◦ 판매자 당 평균 수익 (셀러의 수익) ◦ 평균 거래 건수 ◦ 평균 배송 소요 시간 ◦ 상품 분포 ◦ 판매자 뱃지 비율 ◦ 판매자 나라 분포 ◦ 판매자 당 평균 수익 (수수료) ◦ 파레토 분석(매출 상위 판매자의 매출 비율)
예상 결과물 및 기대 효과
- 예상 결과물
- Vestiaire의 중고거래 동향 및 강점 파악
- 우수 판매자 확보를 위한 액션플랜(전략, 개선점) 마련
- 판매자, 기업용 대시보드
- 대시보드 주요 구성
- 판매자를 위한 트렌드 대시보드
- Vestiaire 직원용 대시보드
- 기대 효과
- Vestiaire Collective 판매자 대상 서비스 개선으로 매출 상승 및 인지도 확대
- 기존 서비스의 불편한 요소들의 개선으로 소비자 만족도 증가
데이터 전처리
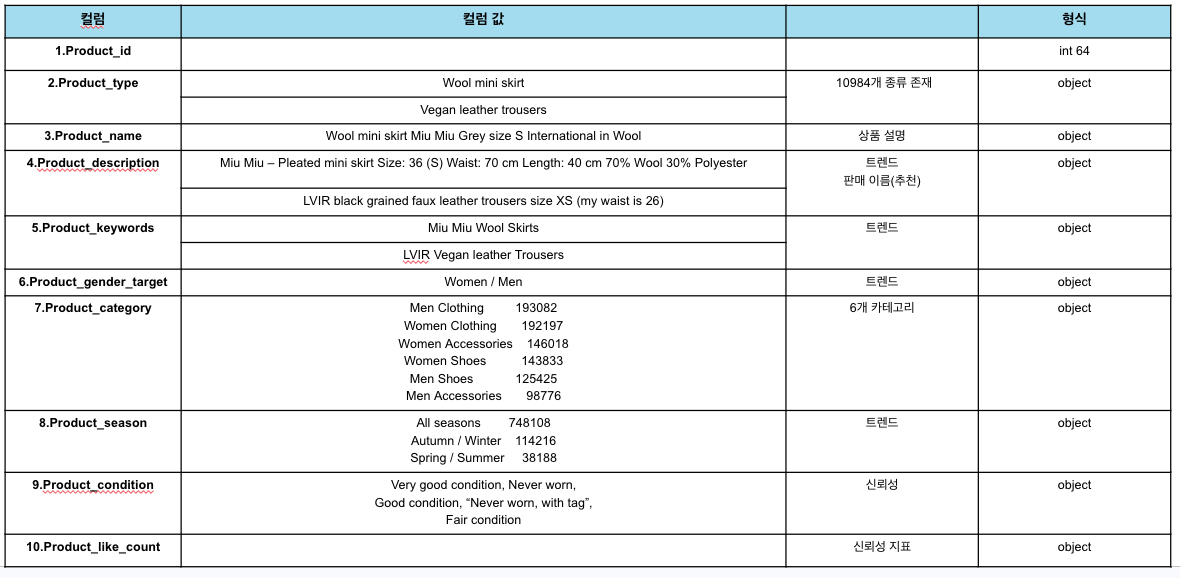
컬럼



결측치 확인
#결측치 확인
# 각 컬럼의 결측치 개수 확인
missing_counts = df.isna().sum()
# 결측치가 있는 컬럼만 필터링
missing_columns = missing_counts[missing_counts > 0]
missing_columns
# 결측치의 고유값 확인
df['컬럼명'].unique()
# 결측치의 고유값 개수 확인
df['컬럼명'].value_counts().head(70)
# 해당 컬럼이 null인 행의 설명
pro = df[df['컬럼명'].isnull()]['product_description']
with pd.option_context('display.max_rows', None, 'display.max_columns', None, 'display.max_colwidth', None):
print(pro)
# with문이 실행될 동안만 셀 너비를 최대로(생략 없이 출력)
결측치 처리
# 결측치 처리 : product_season
#24549752와 14944631인 제품의 product_season 컬럼을 'All seasons'으로 수정
df.loc[df['product_id'].isin([24549752, 14944631]), 'product_season'] = 'All seasons'
# 결측치 처리 : product_material
df.loc[df['product_id'].isin([30896132, 29212261]), 'product_material'] = 'Not specified'
df.loc[df['product_id'].isin([30373177]), 'product_material'] = 'Leather'
df.loc[df['product_id'].isin([30773793]), 'product_material'] = 'Steel'
df['product_material'].value_counts()
# product_color 결측치 multicolour으로 대체
df['product_color'].value_counts()
df.loc[df['product_id'].isin([7152207]), 'product_color'] = 'Multicolour'
# has_cross_border_fees 컬럼의 null 값을 0으로
df['has_cross_border_fees'] = df['has_cross_border_fees'].fillna(0)
# buyers_fees 컬럼의 null 값을 0으로
df['buyers_fees'] = df['buyers_fees'].fillna(0)
# seller_username 컬럼이 null인 행을 제거
df = df.dropna(subset=['seller_username'])
# product_category가 null인 행에서 product_type의 고유값 확인
unique_product_types = df[df['product_category'].isnull()]['product_type'].unique()
unique_product_types
# ['Women Clothing', nan, 'Men Clothing', 'Men Accessories','Women Accessories', 'Men Shoes', 'Women Shoes'] 에서 다음을 반복 실행
filtered_df = df[
(df['product_category'].isnull()) &
(df['product_gender_target'] == 'Women') &
(df['product_type'].str.contains(
r'Polo|jeans|pants|Trousers|Wool cardigan|Wool trousers|Wool harem|Jumpsuit|Lingerie set|Slip|Leggings|Vegan leather mini short|Shorts|Puffer|Camisole|Linen poncho|Cardigan|T-shirt|Shirt|Polo shirt|Vest|Jacket|Silk shirt|Wool dufflecoat|Sweatshirt|Coat|Leather jacket|Bermuda|Slim jean|Straight jeans|Swimwear|Wool pull|Wool jacket|Wool vest|Linen trousers|Parka|Wool peacoat|Knitwear & sweatshirt|Peacoat|Trenchcoat|Linen shirt|Wool sweatshirt|Wool parka|Wool coat|Mid-length dress|Maxi dress|Silk maxi dress|Silk mini dress|Lace mini dress|Silk blouse|Wool jumper|Mini dress|Glitter mid-length dress|Wool top|Silk mid-length dress|Linen mini dress|Silk bra|Corset|Linen mid-length dress|Mid-length skirt|Silk maxi skirt|Lace bra|Leather slim pants|Dress|Linen maxi dress|Cashmere knitwear|Chino pants|Bootcut jeans|Silk top|Short jeans|Skirt|Mini skirt|Silk mid-length skirt|Leather mid-length dress|Maxi skirt|Silk mini skirt|Lace maxi dress|Silk shirt|Sweatshirt|Wool pull|Silk jacket|Wool vest|Knitwear & sweatshirt|Wool sweatshirt|Wool trousers|Wool coat|Knitwear|Straight pants|Top|Blouse|Jumper|Blazer',
case=False, na=False))
]
filtered_df
# product_id가 filtered_df에 있는 경우 product_category을 'Women Clothing'으로 변경
df.loc[df['product_id'].isin(filtered_df['product_id']), 'product_category'] = 'Women Clothing'
# 결측치 처리 : product_keyword
# 브랜드명 + 제품 타입으로 대체
df['product_keywords'] = df['product_keywords'].fillna(df['brand_name'] + ' ' + df['product_type'])
이상치 확인

이상치 처리
# 'seller_earning' == 0인 데이터 삭제,
df2 = df[df['seller_earning'] != 0]
# 'seller_pass_rate'가 마이너스인 데이터 삭제
df2 = df2[df2['seller_pass_rate'] >= 0]'내일배움캠프 > TIL' 카테고리의 다른 글
| [프로젝트 회고] 실전 프로젝트(Tableau)_게임 유저 및 이탈 요인 분석 대시보드 (0) | 2025.03.14 |
|---|---|
| [TIL]250311_데이터 전처리product_type : Men Accessories (0) | 2025.03.11 |
| [TIL]250307_간단EDA(2), 시장조사, KPI 지표 고민.. (0) | 2025.03.07 |
| [TIL]250306_최종 프로젝트 간단 EDA, 배경설정 (0) | 2025.03.06 |
| [TIL]250304_최종프로젝트 도메인 결정 (0) | 2025.03.05 |